You Don't Fail AI PM Interviews Because You Don't Know Enough. You Fail Because No One Told You How You're Being Scored.
I got scored live, without warning - against a real hiring manager rubric. Here's the match, the gaps, and what the scorecard actually looked like.

Let me tell you the real problem.
It’s not that people aren’t learning. There are more AI PM courses, YouTube breakdowns, and LinkedIn frameworks than anyone can consume. Most people I meet in this space are genuinely sharp.
The problem is the gap between knowing and landing.
I’ve sat across from candidates who could recite every AI concept correctly - RAG, evals, multi-agent architectures, and still couldn’t hold the room for 10 minutes on a product question.
That gap is what this series is about.
Here’s the uncomfortable part: there’s no rubric for AI PM interviews. Nobody’s handing candidates a checklist. The question types are inconsistent; the evaluation criteria shift by company. And if you’ve been practicing with random people on Exponent or paying “experts” who’ve never actually evaluated an AI PM candidate, you’re drilling the wrong thing.
So I built a rubric. I built it while at a previous company, where we were bringing people into an AI PM loop but had no standard way to evaluate them. I wrote the scoring guide. Versions of it are still in use today.
That rubric is what we used in this session. And last week, Pranav and Divya - two people from my own cohort - used it to score me.
They didn’t tell me they were scoring me until after I finished answering.
The Setup: A Dojo, Not a Lecture
Divya opened the session with one line: “Tonight is not a lecture. It’s a dojo.”
The agenda was simple - walk through the hiring manager checklist, watch a live mock with real probing, then break into pairs and practice. No slides. No theory. Just reps.
The question Pranav used to open my interview:
“It’s a lot easier in the AI agent world to copy each other’s features. You see it everywhere - Lovable, V0, Replit, all basically indistinguishable. What will you do when a competitor copies your features and offers better pricing?”
Simple question. Loaded with traps. And one which I will ask someone, that means I knew exactly what I needed to land, and still found places where a sharper interviewer could have taken me apart.
The Hiring Manager Checklist: What You’re Actually Being Scored On
Before the match, Divya walked everyone through the three dimensions every answer gets scored on. This isn’t a framework I invented for this session; it’s what interviewers at companies building real AI products are actually looking for.
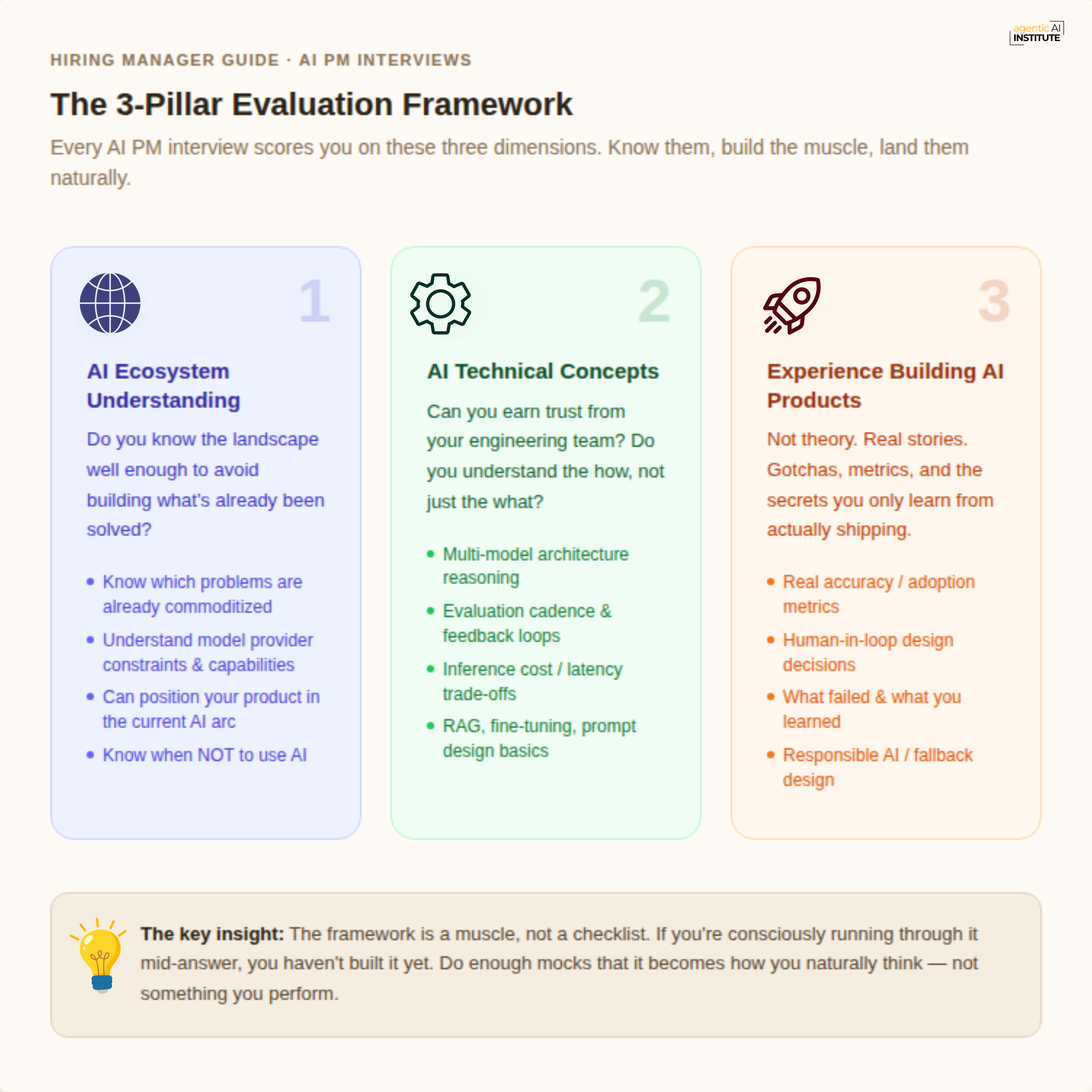
Pillar 1 - AI Ecosystem Understanding: Do you know the landscape well enough to build something that matters? Can you identify what’s already been solved, who the key players are, and where the real whitespace still exists?
A strong answer: you know the difference between model providers, infra layers, and tooling. You understand open source vs. proprietary tradeoffs. You don’t pitch building a coding agent in 2025 like it’s a breakthrough.
Pillar 2 - AI Technical Concepts: Can you hold a real conversation with engineers without bluffing? Do you understand evals, inference tradeoffs, when to use RAG vs. fine-tuning, what hallucination actually means as a design constraint?
A strong answer: you explain these as product realities you’ve navigated, not vocabulary you’ve memorized. You’ve felt the pain of a 43% accuracy baseline and know what it takes to get to 55%.
Pillar 3 - Experience Building AI Products: Have you shipped? Or gone deep enough on a real project that you’ve uncovered secrets - things that surprised you, things that failed, things that only reveal themselves when you’re actually building?
A strong answer: specific metrics, real edge cases, UX decisions that built trust (citations, reasoning toggles, human-in-loop design), and a pricing philosophy rooted in value delivered, not cost of goods.
With that in the room, Pranav started the interview.
The Match - Round by Round

Round 1: The Opening
Pranav: “What will you do when a competitor copies your features and can offer better pricing?”
My play: I didn’t answer the question directly. I pivoted first.
“The journey of product differentiation doesn’t start when you’re defending your product. It starts when you’re building it.”
Then I walked through the product I built in my last role - an autonomous back office for M&A legal work. We narrowed the scope to a single vertical: merger and acquisition legal review. We handled every integration in that space - escrow platforms, law firm systems, Outlook, insurance agencies. By the time a competitor even thinks about entering, they’re already 6 months behind on integrations alone.
The principle: long horizon + end-to-end execution = moat that predates competition.
Why this move works: Interviewers don’t care about the question. They care about your product thinking. Pivoting to a concrete example you know deeply lets you demonstrate both at once. Once you create that tension - let me tell you what I did before, then I’ll answer what you’d do now - they stop tracking the question and start tracking your thinking.
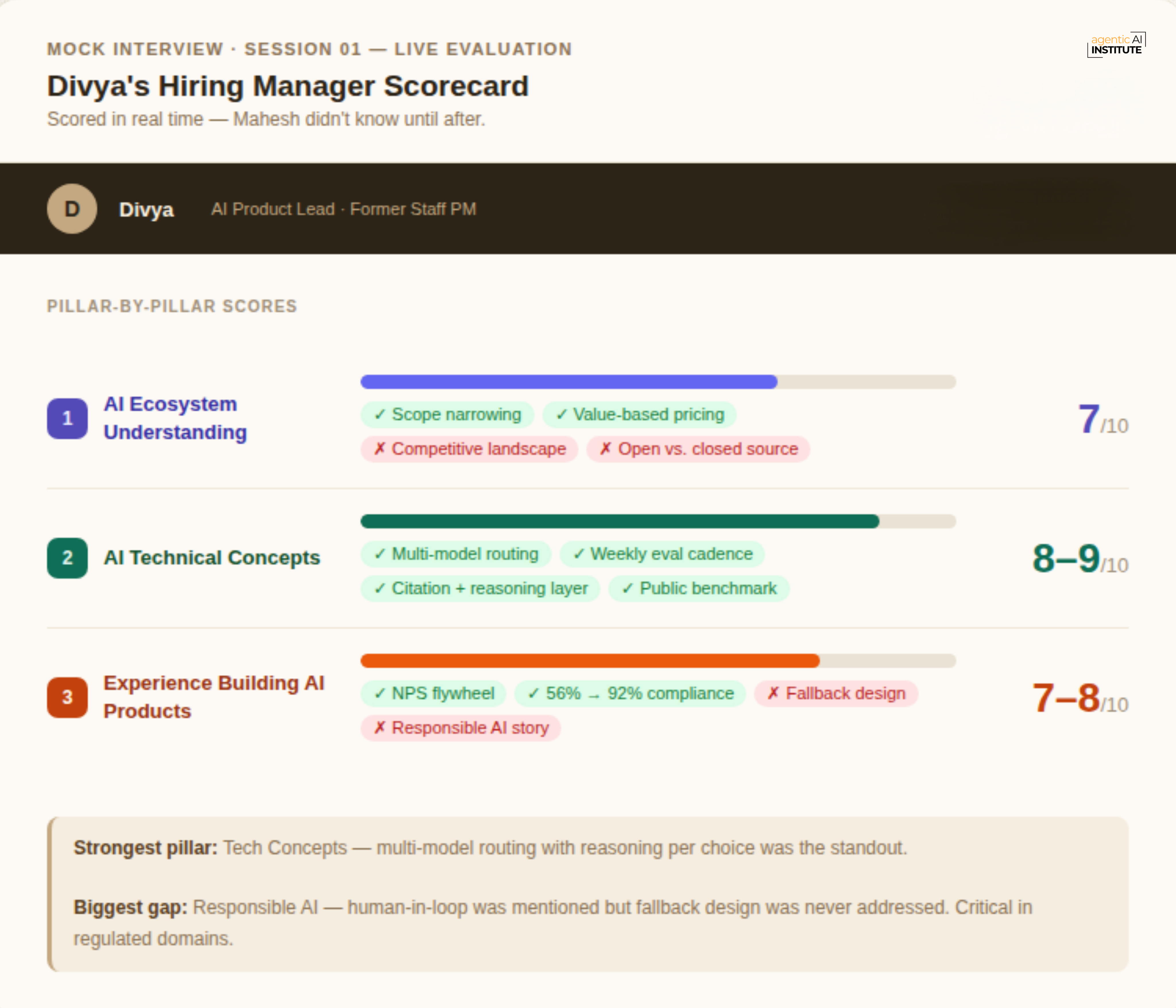
Divya’s live score - Pillar 1 (AI Ecosystem): Strong. Disciplined scoping to one vertical is itself a signal. Generic is a death sentence in AI products, and he knew that.
Gap Divya flagged: He didn’t paint the competitive landscape before jumping to his story. Who else was in the M&A legal AI space? What were they doing wrong? What was the gap? When you skip the landscape and go straight to “here’s what I built,” the interviewer has to guess whether you’ve done your market research. Don’t make them guess.
Round 2: The Pricing Probe
Pranav: “Say inference costs drop 10x in a year. How does your pricing strategy change?”
My answer: “Inference is only a small part of our equation. We’re playing the value game, not the pricing game. A lawyer charges $1,000 for the same job we do for $10. Even if I drop to $1, the delta from the customer’s perspective is still enormous.”
I also named five features already in the pipeline, continuous learning, playbook encoding, and more, that would ship before a pricing change would matter.
The vulnerability I caught myself on, after the session:
“If Pranav had pushed harder - if he’d pointed out that a complex AI workflow runs thousands of model calls, not one - my inference cost isn’t $10, it’s potentially $1,000. A 10x reduction would matter a lot in that case. He didn’t catch me there. But a sharp interviewer would have.”
This is worth noting: catching your own holes in real time, unprompted, is itself a senior PM signal. It’s not a natural gift. It’s a practiced muscle.
Divya’s score - Pillar 2: Smart reframe. Value-based argument was correct. But the inference-call volume vulnerability was a real crack in the logic.
Round 3: The Technical Depth Test
Pranav: “What’s your affinity toward specific models? Any preference for the features you built?”
My answer - the buffet of models:
We don’t use one model. We use a routing engine that calls different models based on the task:
Contract detection: Haiku - fast, cheap, doesn’t eat into TPM/RPM limits
Reasoning and risk analysis: Opus 4 - worth the cost where accuracy matters most
Anomaly detection: GPT-5.5 -best in class for that specific task
We started with 100–200 samples from in-house lawyers at a PE firm. Baseline accuracy: 43%. Target: 55%. We ran weekly permutations until we got there, then improved 10% month-on-month. At the time of this session, iterations are in the four digits.
When Claude Code launched, and everyone said “redlining is now commoditized,” we open-sourced our benchmark dataset and asked the question publicly. Claude Code scored 2.7 out of 5. We scored 4.6.
“Customers can copy our prompts. They can copy our UX. They cannot copy 4,000 iterations of evaluation.”
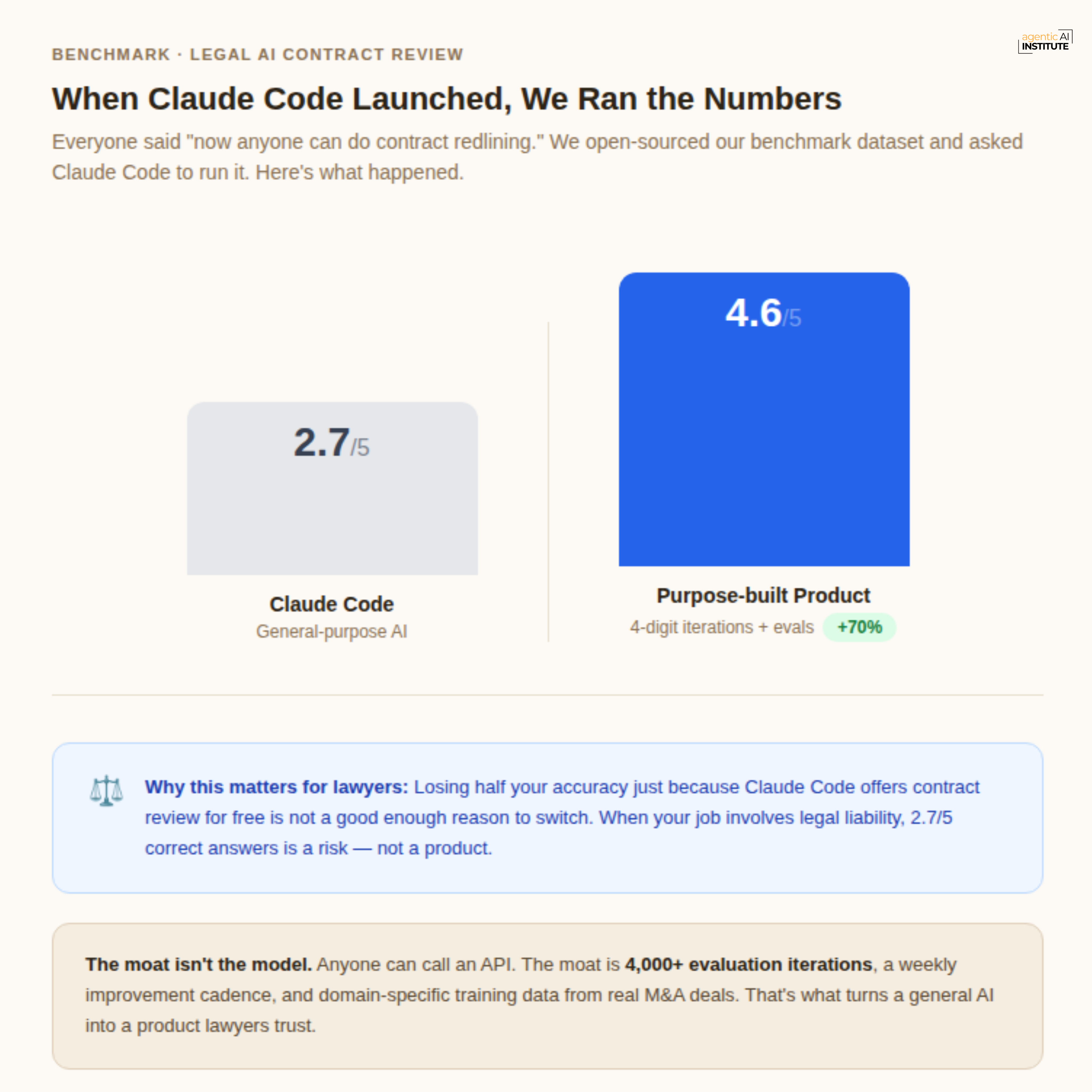
Divya’s score - Pillar 2: Strongest showing of the session. Multi-model routing with reasoning for each choice. Real eval cadence with real numbers. Public benchmark that turns a defensive claim into a documented moat. Would score this 8–9.
Gap flagged: Never addressed the open source vs. closed source decision. Why not Llama? In 2025, that’s a fair question, and “we chose closed” without reasoning is a missed chance to show ecosystem depth.
The Value-as-Product Principle
Also, I brought in a second use case here - certificate of insurance compliance for a property management company.
Before our product: 56% compliant. After: 92%. Zero manual steps in the workflow. Tenants email their insurance certificates → system checks coverage → human brought in only for exceptions → dashboard updated.
The principle I named: “We didn’t offer AI as a product. We offered value as a product.”
There’s a real difference. AI as a product means you’ve built a tool people have to come to. Value as a product means you’ve integrated so deeply into their workflow that the AI is invisible; the outcome is what they experience.
Divya’s score - Pillar 3: Strong on flywheel and impact. The NPS loop is real: contract uploaded → AI identifies risk → citations shown → reasoning displayed → lawyer adds their own reasoning → that reasoning feeds back into the system. Each iteration makes the product smarter and more locked to that firm’s thinking. A competitor isn’t just behind on features - they’re behind on months of encoded institutional knowledge.
Gap flagged: No fallback design. What happens when the AI is definitively wrong? In M&A legal, where a missed risk isn’t a bad recommendation, it’s a lawsuit - the responsible AI story is part of your moat. Audit trails, guardrails, human-in-loop not just for exceptions but for confidence calibration. Mahesh touched human-in-loop but didn’t connect it to the responsible AI argument. That’s the gap.
Round 4: Audience Q&A - The Hard Probes
Neha on data security: “M&A involves extremely sensitive information. How does the product prevent leakage?”
Three-layer answer: integration with an escrow platform so neither party’s lawyers have raw data access, on-premise hosting option for sensitive deals that can’t touch a cloud provider even under encryption, and a $60M insurance policy covering breach scenarios.
Specific. No hedging. No “we take security seriously.”
Mukul on the well-funded competitor: “Your answer assumes the competitor is a surface-level clone. What if it’s Google - equally funded, equally capable?”
“Google isn’t a law firm. They can’t iterate on M&A evaluations without access to M&A deals. And even if they ship the software, every law firm has encoded 6 months of their own reasoning into our system. To replace us, they’d need each firm to re-encode all of that from scratch. That’s the moat. Not the model - the accumulated judgment embedded in the product.”
This is the answer that separates candidates. Anyone can say “we have proprietary data.” Far fewer can explain why that data creates switching costs that survive even the best-funded competitor in the room.
The Sharpest Question of the Night - What Both Formats Usually Missed
After the interview, AK asked something that cuts to the heart of how people fail these loops:
“This question could have been answered completely without mentioning AI at all. How do you know which direction to take?”
My answer: “If you’re in an AI PM interview loop, the interviewer is looking for your AI-first thinking. You can answer a moat question generically, but you’ll be leaving a signal on the table. The title of the round tells you where to land.”
Then the line that matters most:
“The goal isn’t to have the framework memorized. The goal is for this to become subconscious - so when you’re in the room, you’re just thinking, not reciting.”
This is the entire game. The three pillars aren’t a checklist. They’re a lens. You do enough mocks that you stop thinking have I hit all three dimensions and start just... thinking about AI products well. The framework should disappear into your muscle memory.
Divya’s Honest Scorecard
What the Practice Pairs Showed
After the demo, participants broke into pairs with a version of the question: “There’s no moat in AI agents - everyone builds on the same models and it’s easy to copy. How do you build defensibility?”
Three things stood out across every pair:
The gap between knowing and doing is structural thinking under pressure. Most people understand what a moat is. Far fewer can build the argument from scratch, in 10 minutes, on a live call, with follow-up questions arriving mid-sentence. The ones who could had practiced. The ones who couldn’t had only read.
Personal examples beat frameworks every time. The strongest answers came from people who stopped trying to be comprehensive and started telling a real story, even a prototype story. One participant pivoted immediately to something they’d built in the course and walked through their own moat layers. It wasn’t polished. It was real. Interviewers remember experience. Frameworks they’ve heard before.
Your comfort zone is your trap. One pair went deep on AI concepts -model routing, evals, latency tradeoffs - but thinned out when pushed on business outcomes. Another was strong on pricing and value, but couldn’t go technical when probed on how they’d build the eval harness. Both are gaps. The checklist exists precisely because candidates naturally over-index on what they know best.
One more tactical thing Pranav shared from his own real interviews that most people aren’t doing: “I ask if I can share my screen, and I show a prototype. One interviewer asked how long it took to build. The whole conversation shifted. You stop explaining what you built and start showing it.”
The 5-Step Drill Before Your Next AI PM Interview
This is the actual prep sequence, not a reading list:
